
Was sind Indexierung, Klassifizierung und Taxonommie?
Indexierung
Als indexieren bezeichnet man bei der inhaltlichen Erschließung die Tätigkeit, ein Dokument mit geeigneten Beschreibungen (Deskriptoren) zu versehen. Durch eine Indexierung kann ein Dokument schneller und leichter wiedergefunden werden (vgl. Pfund o. D.).
Klassifizierung
Als Klassifizierung bezeichnet man den Vorgang, Objekte anhand ihrer Eigenschaften einer Klasse innerhalb einer Anzahl diskreter Klassen zuzuweisen. Hierbei werden Regeln genutzt, die es erlauben, Merkmale für eine Unterscheidung verschiedener Klassen festzulegen. Üblicherweise sind dies physikalische Unterscheidungsmerkmale (vgl. „classification“ o. D.).
Taxonomie
Taxonomie ist ein einheitliches Verfahren oder Modell, mit dem Objekte nach bestimmten Kriterien klassifiziert, das heißt in Kategorien oder Klassen eingeordnet werden. Wissenschaftliche Disziplinen verwenden den Begriff der Taxonomie für eine in der Regel hierarchische Klassifikation (Klassen, Unterklassen usw.) (vgl. Antwerpes et al. 2016).
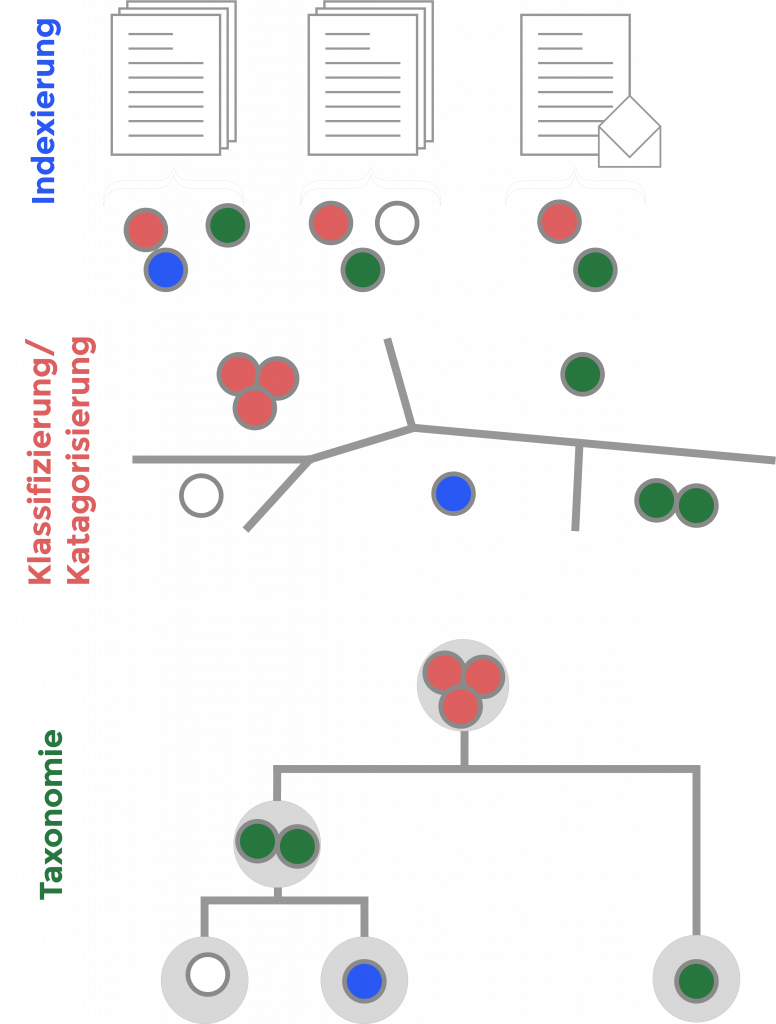
Quelle: Eigene Darstellung, in Anlehnung an Textbasis: Indexierung-> „Dokument mit geeigneten Beschreibungen“, Klassifizierung-> „Objekte anhand ihrer Eigenschaften einer Klasse innerhalb einer Anzahl diskreter Klassen zuzuweisen, Taxonomie-> „Objekte nach bestimmten Kriterien klassifiziert“
Einordnung in das AIIM-Modell
Enterprise Collaboration Managements benötigen Informationsarchitekturen in Verbindung mit einem Suchindex. Dies erhöht den Nutzwert sozialer Businessanwendungen und schafft den notwendigen Kontext, um Anwendern die notwendige Orientierung innerhalb der Organisation und prozessunterstützenden Aufgaben zu bieten. Somit ist es für das Wissensmangement notwendig, dass Informationen ausreichend selktiert werden und effizient entscheidungsrelevante Informationen identifiziert werden, um sie im individuellen Anforderungskontext zuvestehen, damit dies in eigenes Wissen überführt werden kann, um auf dessen Grundlage handeln zu können (vgl „Wissensmanagement beflügelt“ 2014).
Die folgende Abbildung zeigt die Einordnung der 3 Themengebiete im AIIM Modell.
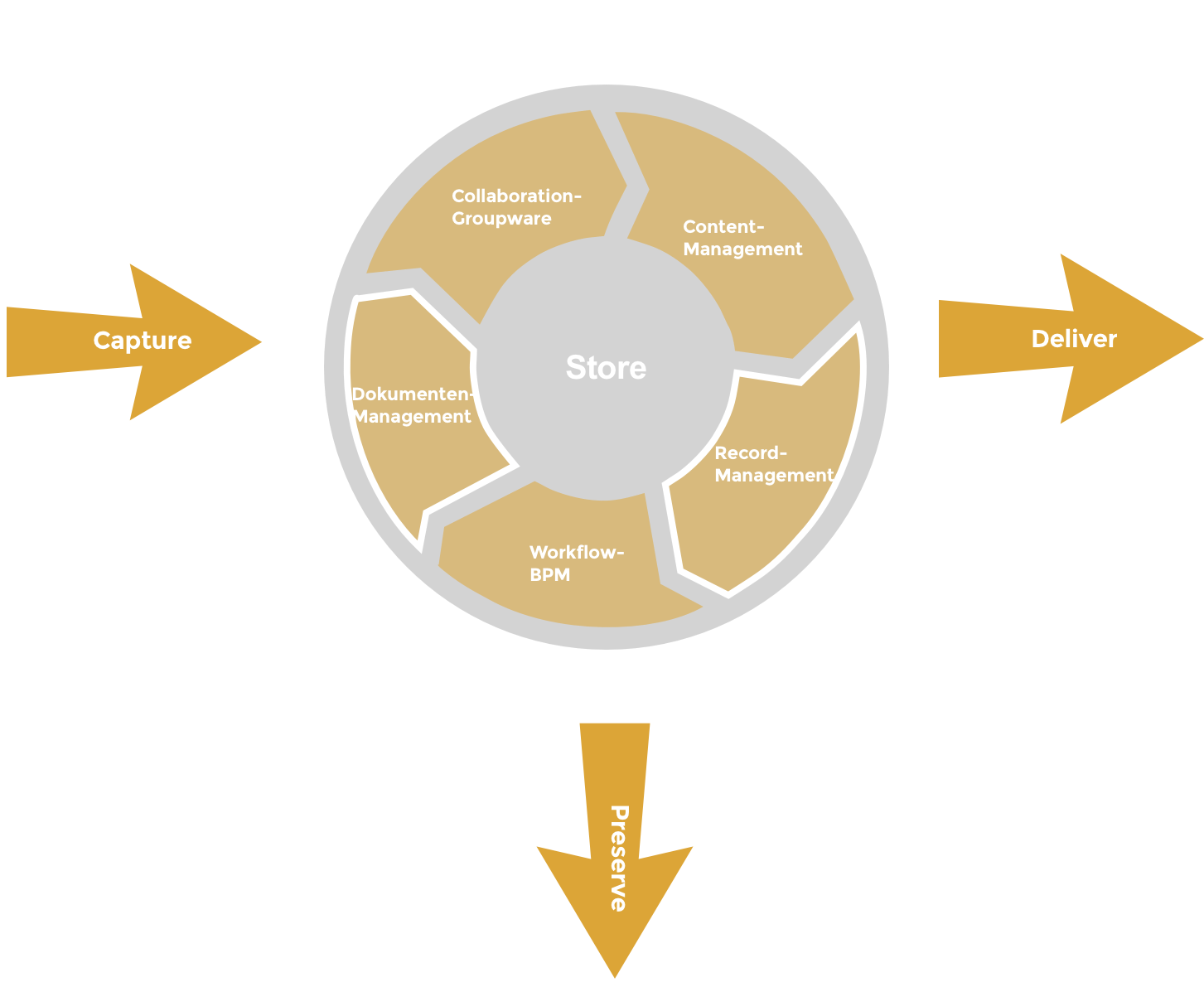
Quelle: Eigene Darstellung, in Anlehnung an AIIM-Model
Darunter lassen sich die Anwendungsfelder der Indexierung, Klassifizierung und Taxonomie im engeren Sinn mit Dokumentenmanagement und Record-Management miteinander verbinden.
Arten der Indexierung
Die Manuelle Indexierung, Intellektuelle Indexierung oder Verschlagwortung ist ein Verfahren der Sacherschließung von Dokumenten, bei der einem Dokument repräsentative Schlagwörter (engl. „Subjects“) durch einen Indexierer zugewiesen werden. Die manuelle Indexierung wird von Experten mittels Terminologielisten und ähnlichen Regelwerken kontrollierten Vokabulars durchgeführt; sie gestattet eine Sprachanalyse individueller Formulierungen und eine Synonymvergabe, besitzt aber den Nachteil, dass sie aufwendig, langsam und teuer ist, ihre Qualität von der konsistenten Arbeitsweise des Personals abhängt und der vordefinierte Deskriptorwortschatz statisch ist. Zudem muss der Benutzer das Indexierungsvokabular kennen, um Dokumente zu recherchieren (vgl. Pfund o. D.).
Volltextindexierung ist die (automatische) Erfassung sämtlicher Wörter eines Textes im Index. Ausgenommen davon sind in der Regel Stoppwörter.[6]
(Stoppwörter nennt man im Information Retrieval Wörter, die bei einer Volltextindexierung nicht beachtet werden, da sie sehr häufig auftreten und gewöhnlich keine Relevanz für die Erfassung des Dokumentinhaltsbesitzen.)(vgl. Pfund o. D.).
Bei der computergestützten Indexierung (auch Indizierung) werden Deskriptoren maschinell vorgeschlagen und manuell ausgewählt. Hierbei erfolgt die Indexierung durch Computer mit Vor- oder Nachbereitung durch Menschen bzw. in Interaktion mit Menschen (vgl. Pfund o. D.).
Methoden des Indexieren
Das freie Indexieren
Beim freien Indexieren können die Deskriptoren frei gewählt werden. In der Regel gibt es dabei aber auch Auflagen. Zum Beispiel, dass der Deskriptor deutsch sein muss und nur in Einzahl verwendet werden darf (vgl. Pfund o. D.).
Das kontrollierte Indexieren
Beim kontrollierten Indexieren dürfen die Deskriptoren nur aus einem bestimmten, kontrollierten Vokabular genommen werden. Ein kontrolliertes Vokabular ist zum Beispiel ein Thesaurus (NASA Thesaurus, INFODATA Thesaurus) oder ein Schlagwortkatalog (vgl. Pfund o. D.).
Die syntaktische oder strukturierte Indexierung
Die syntaktische oder strukturierte Indexierung ist ein Verfahren zur Indexierung von Texten für die Informationswiedergewinnung, bei dem die sprachlichen (syntaktischen) Beziehungen zwischen den Deskriptoren kenntlich gemacht werden (vgl. Pfund o. D.).
Die gleichordnenden Indexierung
Bei der gleichordnenden Indexierung (engl. coordinate indexing) werden einem Dokument bei der Indexierung mehrere Deskriptoren unstrukturiert und gleichrangig zugeordnet (vgl. Pfund o. D.).
Taxonomien
Taxonomien werden genutzt, um Geschäftsobjekte zu strukturieren und verschiedene Sichten zu erzeugen. Taxonomien sind für die Entwicklung von erheblicher Bedeutung: Sie erleichtern den Umgang mit Einzelfällen und ermöglichen summarische Aussagen, die bis hin zu einer Erklärung von Zusammenhängen führen können. Sie zwingen zur Klarheit über die Unterschiede zwischen den Kategorien und führen dadurch zu einem besseren Verständnis des Untersuchungsbereichs (vgl „Data Vault Anti-patterns“ o. D.).
Taxonomiebeispiele:
- Projektorientiert
- Vorgangsorientiert
- Prozessorientiert
- Organisationorientiert
- Dokumentenklassenorientiert
(vgl. „Lehrveranstaltungen/IuG_SoSe2007/folien“ 2007).
Problematik von Taxonomien:
- Keine Abbildung von Synonyen
- Zuordnung verschiedener Oberthemen
(vgl. „Taxonomie“ 2022).